Building the Model

The data set used for our model contains a detailed play-by-play account of every single play ran over the course of 10 season. It contains, geographical and date information, the type of play that was called, the number of yeards gained from said play, down, clock and field positioning, among others. It also contains offensive stats on each player directly involved in the play, such as passing and rushing yards, yards ran after a catch, etc, and defensive stats, such as fumbles and interceptions, and of course play outcome, e.g. touchdown, field goal, etc.
In order to create a model that can predict which play is the likeliest to be called, we reasoned that any information relating to the state prior to calling the play would be critical in informing the decision to run a pass or a run play, or alternatively to kick a field goal or punt. We limited our predictions to one these for several reasons:
- Kickoffs were removed as they only occur at the beginning of the game/half or after a scoring drive. Decisions don't factor in other then the type of kick, e.g. long, short or onside kick.
- Edge cases, such as QB kneel or spiking where also dropped as occur under specific circumstances.
Play Breakdown - All Plays
Feature Selection
The original dataset contains 254! features. After cleaning the data and supplementing with weather information, we focused on features, which would be predicted to influence play calling.
Intrinsic Features
The goal of a play is to gain as many yards as possible, 10 at a minimum, generally over the course of 3 downs, as a team marches down the field towards scoring a touchdown or a fieldgoal. As such we would expect "down" and "distance-to-go" to be critical in deciding which play to call. Passes net more yards on average, but short distances are typically easier to obtain running the ball. Time remaining in the half or in the game and score differential are also a crucial considerations. Finally, we reasoned that field positioning could be important, but largely dependent on other factors, such as time remaining and the number of time outs a team possesses, which we also included as our inital set of feature:
- Yard line (yardline_100)
- Quarter (qtr)
- Time remaining in the half (half_seconds_remaining)
- Time remaining in the game (game_seconds_remaining)
- Current down (down)
- Yards-to-go to 1st down or TD (ydstogo)
- Timeouts remaing, possession team (posteam_timeouts_remaining)
- Timeouts remaing, defending team (defteam_timeouts_remaining)
- Score differential (score_differential)
Extrinsic Features
As discussed earlier, weather plays a critical part in deciding which play to call. For example, under heavy rains or strong winds, loss of grip and visibility may favor running plays. We sought out to detemine whether weather conditions could improve our learning model. The following game time weather parameters were included:
- Temperature
- Precipitation (amount)
- Snow (amount)
- Wind speeds
- Visibility
- Humidity
To facilitate the exploratory data analysis phase, we used the extremely useful library, pandas_profiling. For each feature in our dataset, the following statistics - if relevant for the column type - were obtained:
- Essentials: type, unique values, missing values
- Quantile statistics like minimum value, Q1, median, Q3, maximum, range, interquartile range
- Descriptive statistics like mean, mode, standard deviation, sum, median absolute deviation, coefficient of variation, kurtosis, skewness
- Most frequent values
- Histogram
- Correlations highlighting of highly correlated variables, Spearman and Pearson matrixes
None of the features we intuitively selected showed any significant correlation, except for half_game_remaining and qtr. However, a number of features include several outliers, especially the score differential. We can verify that these extreme values are from actual games, and not entry errors. For example, the largest score differential (59 points) was from an October 19th, 2009 game between the New Englan Patriots and the Tennessee Titans, which ended with a score of 59-0 in favor of the Patriots. Interestingly, the largest distance-to-go value (50) occured on a 3rd and 50 situation, in a game between the Washington Redskins and the Cincinnati Bengals on September 23rd, 2012.
Correlation Matrix
Feature Box Plot
Models
Since there are four possible play outcomes, this boils down to a multi-class classification problem. Given a set of pre-existing game and weather conditions, what is the predicted play call? After cleaning and aggregating the data, we scaled the features and ran multiple algorithms, encompassing regression, ensemble and boosting classifiers:
- Logistic Regression
- Logistic Regression w/ Cross Validation
- Stochastic Gradient Descent (SDG)
- K-Nearest Neighbor
- Bagging meta-estimator
- AdaBoost
- XGBoost
- Decision Tree
- Extra Tree
- Random Forest
Accuracy Scores
Model Diagnosis
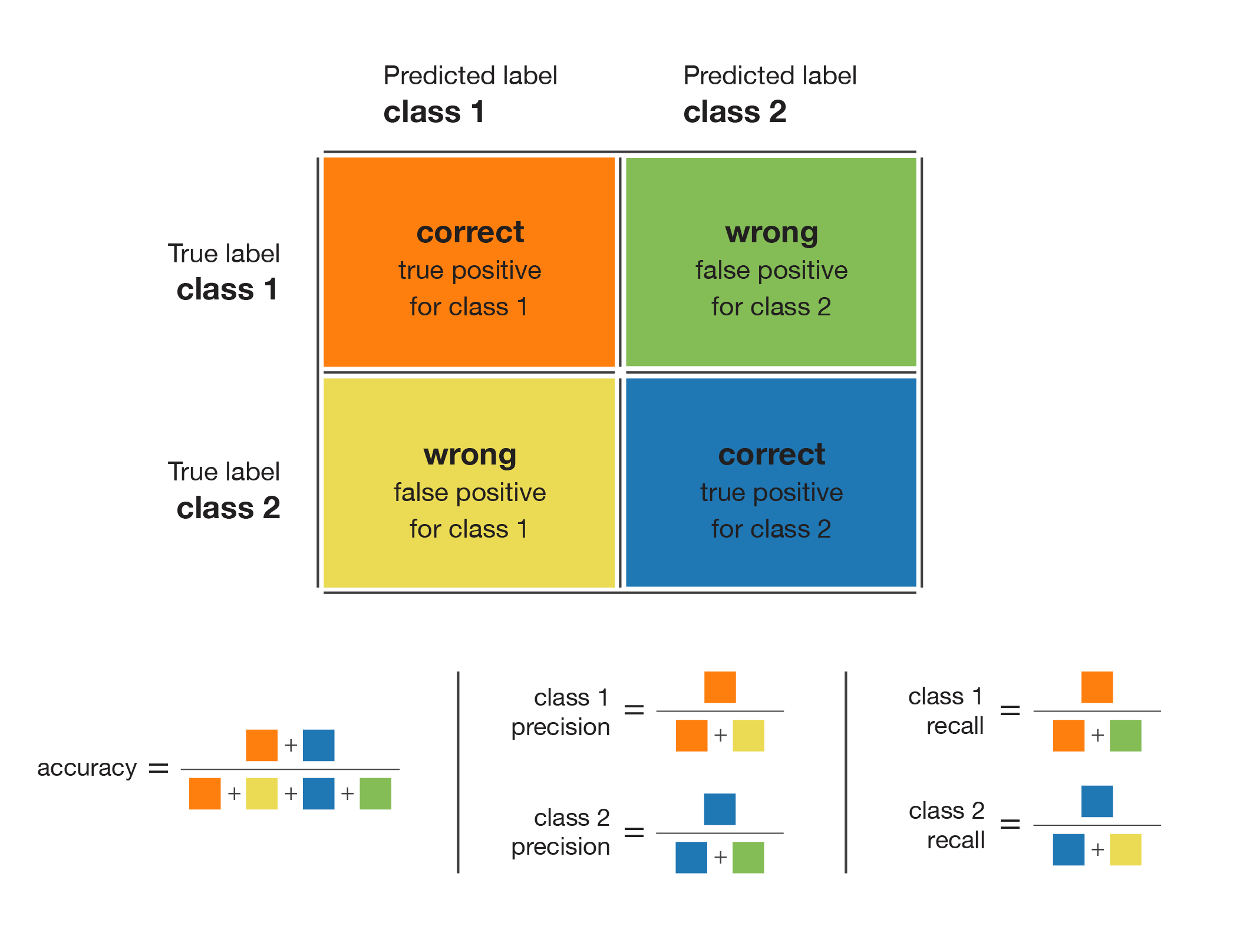
We found that the Random Forest classifer gave the best accuracy score (71.0%), followed closely by the Extra Tree classifier (70.3%). However, because of the imbalanced nature of our classes, accuracy score is not necessarily useful to evaluate the overall performance of the model (i.e. How well does the model recognize each class?). To get a better understanding of the model's performance, we also plotted the confusion matrix, which tells how well the models does for each class. The confusion matrix also gives us three important metrics: precision, recall and F1 score.
- Precision: What proportion of predicted positives is truly positive? For example, the precision for the class "pass" is the number of correctly predicted pass plays out of all predicted pass plays.
- Recall: What proportion of actual positives is correctly classified? For example, of the plays that are actually runs, how many were correctly classified as runs?
- F1 score: The harmonic mean of the precision and recall.
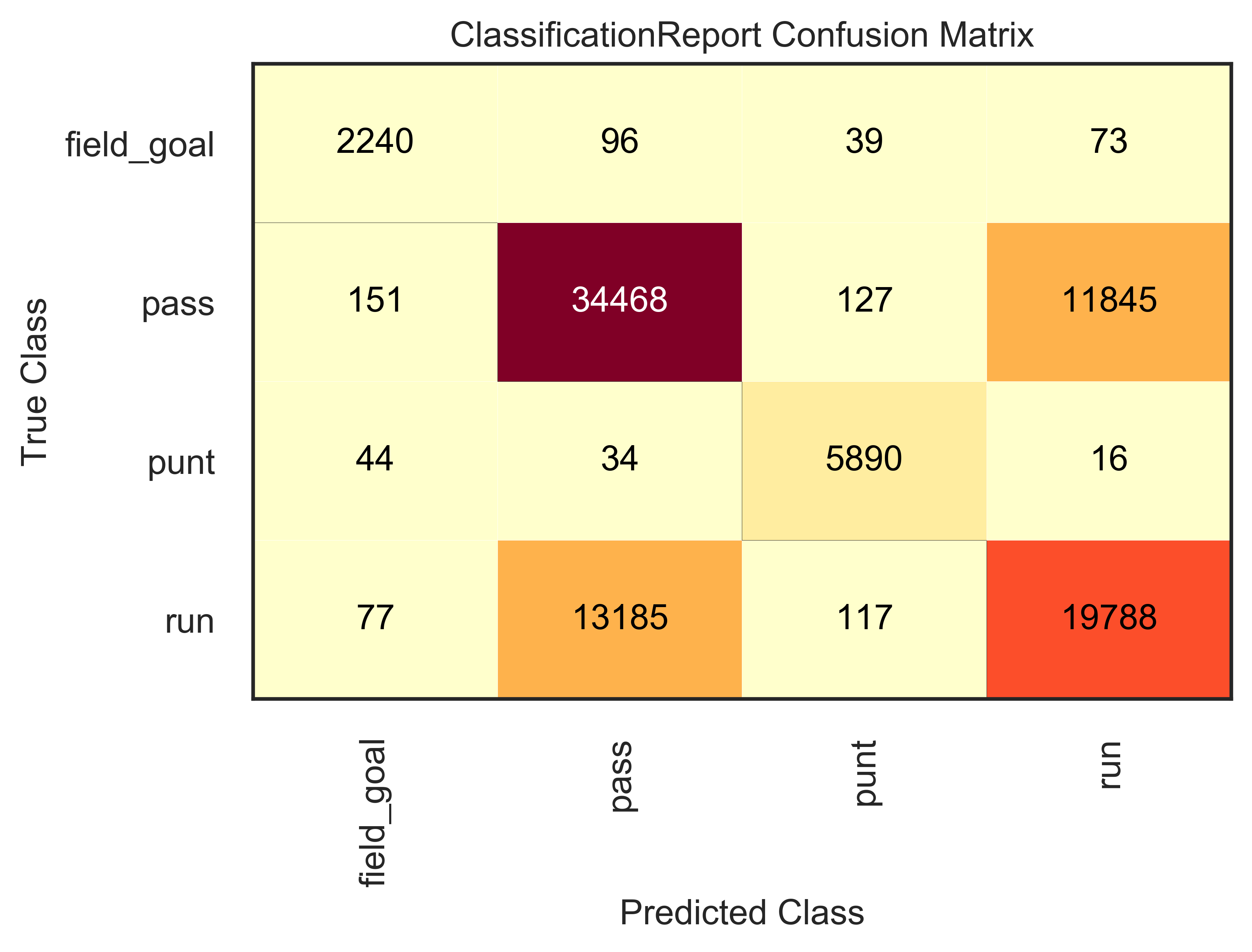
From the confusion matrix, we can see that the model performs extremely well when it comes to classifying punts and field goals, with precision scores of 96% and 89%, respectively, which is the percentage of predicted punts and field goals that were actually such. Conversely, the recall score was 98% and 91%, respectively, indicating the percentages of actual punts and field goals that were actually correctly classified. This suggests that the model is good at handling both of these classes.
For pass plays the model's performance drops significantly, with precision and recall scores of 72% and 74%, respectively. This means that 72% of predicted pass plays were actually pass plays and 74% of actual pass plays were corretly classified. The Prediction Error Chart shows that ~25% of pass plays were classified as "runs".
As for runs, the models was able to correctly classify only 60% of run plays (recall). 62% of predicted runs were in fact run plays (precision), as the model struggled to differentiate from pass plays, as seen in the Prediction Error chart.
Model Improvement
One of the potential issues in training our model, is class imbalance. To tackle this, we decided to generate synthetic data, using the SMOTE (Synthetic Minority Over-sampling Technique) method, which consists in creating new synthetic points from the minority class to increase its cardinality. It works by creating synthetic samples from the minor class instead of creating copies. The algorithm selects two or more similar instances (using a distance measure) and perturbing an instance one attribute at a time by a random amount within the difference to the neighboring instances.
Balancing the classes before training significantly improved the model's overall accuracy, from 71% to 86.3%. More importantly, we saw a significant improvement in performance for the "run" class. As seen in the classification report, precision and recall scores increased to 73.1% and 73.5%, respectively. We also saw a slight improvement in precision for the "pass" class (72.1% to 73.6%), but interestingly at the expense of recall, which decreased slightly from 74.1% to 72.3%. Both precision and recall scores for "punt" and "field_goal" classes also showed improvements to almost perfect scores.
Random Forest Accuracy Score - Before and After Resampling
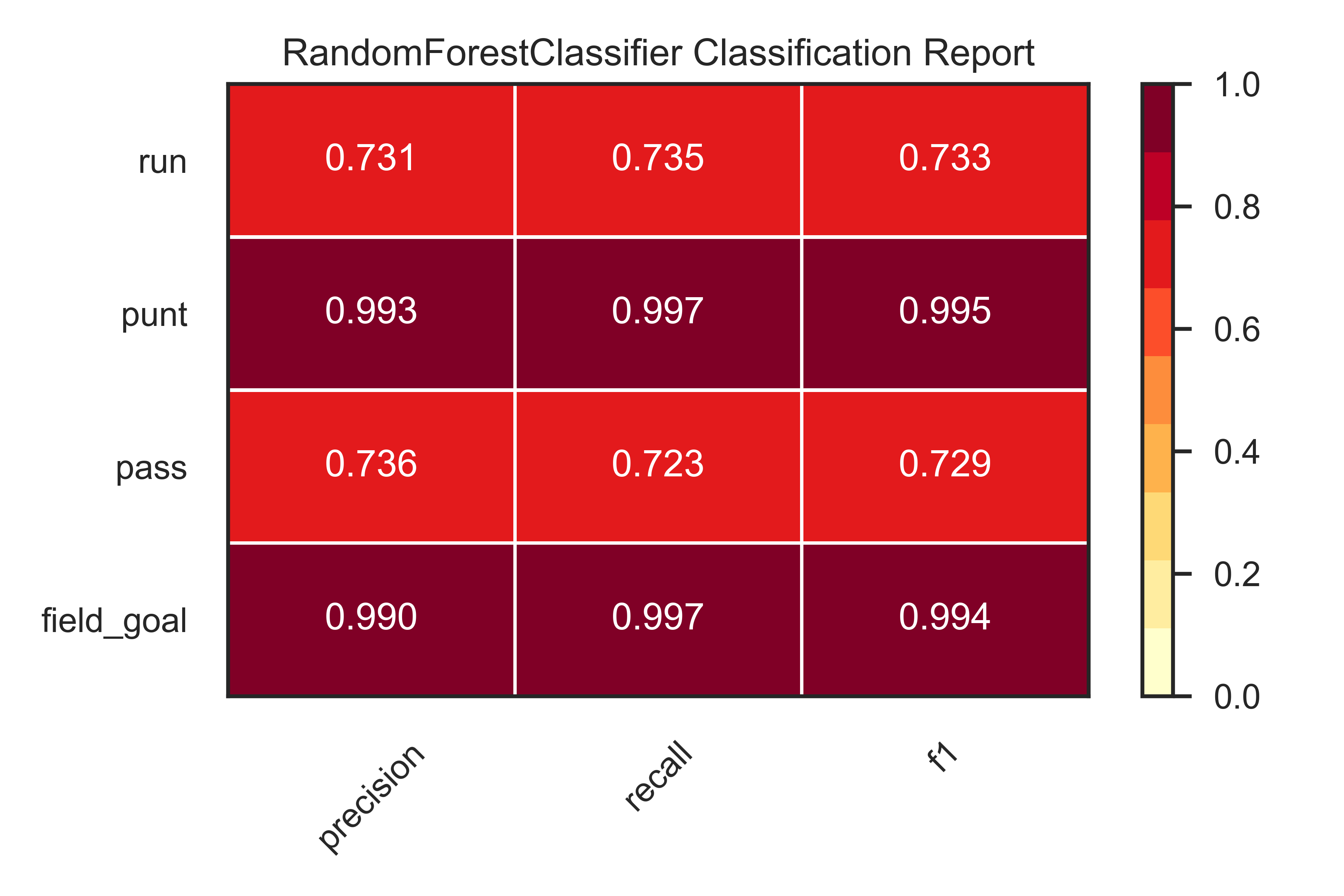
Feature Importance
Bagged decision trees like Random Forest and Extra Trees can be used to estimate the importance of features. We further improve on the model using the Recursive Feature Elimination (RFE) method with cross validation (CV) on the balanced dataset. RFECV works by recursively removing attributes and building a model on those attributes that remain. It uses the model accuracy to identify which attributes (and combination of attributes) contribute the most to predicting the target attribute.
After fitting, RFECV exposes an attribute grid_scores_ which returns a list of accuracy scores for each of the features selected. We can use that to plot a graph to see the number of features which gives the maximum accuracy for the given model. By looking at the plot we can see that inputting 7 features to the model gives the best accuracy score. RFECV also exposes support_, which is another attribute to find out the features which contribute the most to predicting. The final random forest classifier model was built using the features below: